39 min de lectura
Visualizando datos con Python: crímenes en Philadelphia
En esta oportunidad se practica visualización y estudio de datos con el registro de crímenes en Philadelphia, que se puede descargar desde el sitio web de Kaggle. Para este ejercicio vamos a descubrir qué nos dice la data y hacer inferencias usando:
- Python
- Pandas
- Seaborn
- Matplotlib
- Leaflet
Primero, importamos las librerías:
# Lectura de datos y visualización de gráficos
import pandas as pd
import seaborn as sns
# Para interpretar fechas
from datetime import datetime
#Para controlar las propiedades de nuestros gráficos
import matplotlib.pyplot as plt
# Para visualizar imagenes
import matplotlib.cbook as cbook
from matplotlib.pyplot import imread
# Para visualizar mapas usando leaflet
from ipyleaflet import *
Por otro lado, necesitaremos interpretar fechas, así que definimos un lambda para hacerlo de manera funcional mas adelante.
def parseDatetime(x):
return datetime.strptime(x, "%Y-%m-%d %H:%M:%S")
parsedate = lambda x: parseDatetime(x)
Leemos el registro de crímenes con pandas y echamos un primer vistazo a la tabla con el método DataFrame.head.
crimeData = pd.read_csv(\
filepath_or_buffer="../resources/crime.csv",\
header=0,\
names=[\
'Dc_Dist',\
'Psa',\
'Dispatch_Date_Time',\
'Dispatch_Date',\
'Dispatch_Time',\
'Hour',\
'Dc_Key',\
'Location_Block',\
'UCR_General',\
'Text_General_Code',\
'Police_Districts',\
'Month',\
'Lon',\
'Lat'\
],\
dtype={\
'Dc_Dist':str,\
'Psa':str,\
'Dispatch_Date_Time':str,\
'Dispatch_Date':str,\
'Dispatch_Time':str,\
'Hour':float,\
'Dc_Key':str,\
'Location_Block':str,\
'UCR_General':str,\
'Text_General_Code':str,\
'Police_Districts':str,\
'Month':str,\
'Lon':float,\
'Lat':float\
},\
parse_dates=["Dispatch_Date_Time"],\
date_parser=parsedate\
)
crimeData.head()
| Index | Dc_Dist | Psa | Dispatch_Date_Time | Dispatch_Date | Dispatch_Time | Hour | Dc_Key | Location_Block | UCR_General | Text_General_Code | Police_Districts | Month | Lon | Lat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 18 | 3 | 2009-10-02 14:24:00 | 2009-10-02 | 14:24:00 | 14.0 | 200918067518 | S 38TH ST / MARKETUT ST | 800 | Other Assaults | NaN | 2009-10 | NaN | NaN |
| 1 | 14 | 1 | 2009-05-10 00:55:00 | 2009-05-10 | 00:55:00 | 0.0 | 200914033994 | 8500 BLOCK MITCH | 2600 | All Other Offenses | NaN | 2009-05 | NaN | NaN |
| 2 | 25 | J | 2009-08-07 15:40:00 | 2009-08-07 | 15:40:00 | 15.0 | 200925083199 | 6TH CAMBRIA | 800 | Other Assaults | NaN | 2009-08 | NaN | NaN |
| 3 | 35 | D | 2009-07-19 01:09:00 | 2009-07-19 | 01:09:00 | 1.0 | 200935061008 | 5500 BLOCK N 5TH ST | 1500 | Weapon Violations | 20 | 2009-07 | -75.130477 | 40.036389 |
| 4 | 09 | R | 2009-06-25 00:14:00 | 2009-06-25 | 00:14:00 | 0.0 | 200909030511 | 1800 BLOCK WYLIE ST | 2600 | All Other Offenses | 8 | 2009-06 | -75.166350 | 39.969532 |
Tipos de crímenes
Accedemos a la columna de categorías de crímenes y con el método Series.value_counts obtenemos el número de registros por cada tipo de crimen.
# Cantidad de crímenes en cada categoría
crimesCountedByType = crimeData.Text_General_Code\
.value_counts()
crimesCountedByType.head()
All Other Offenses 437581
Other Assaults 277332
Thefts 257923
Vandalism/Criminal Mischief 200345
Theft from Vehicle 171135
Name: Text_General_Code, dtype: int64
Cantidad de crímenes por categoría
Utilizando la serie anterior, hacemos un gráfico de barras con el método seaborn.barplot, para poner en cotexto estos datos de forma visual.
# Seteamos el tamaño del gráfico
plt.subplots(figsize=(10, 10))
g = sns.barplot(x=crimesCountedByType.index.tolist(), y=crimesCountedByType.values);
# Hacemos que la leyenda sea mas facil de leer
g.set_xticklabels(rotation=90, labels=crimesCountedByType.index.tolist(), fontsize=12);
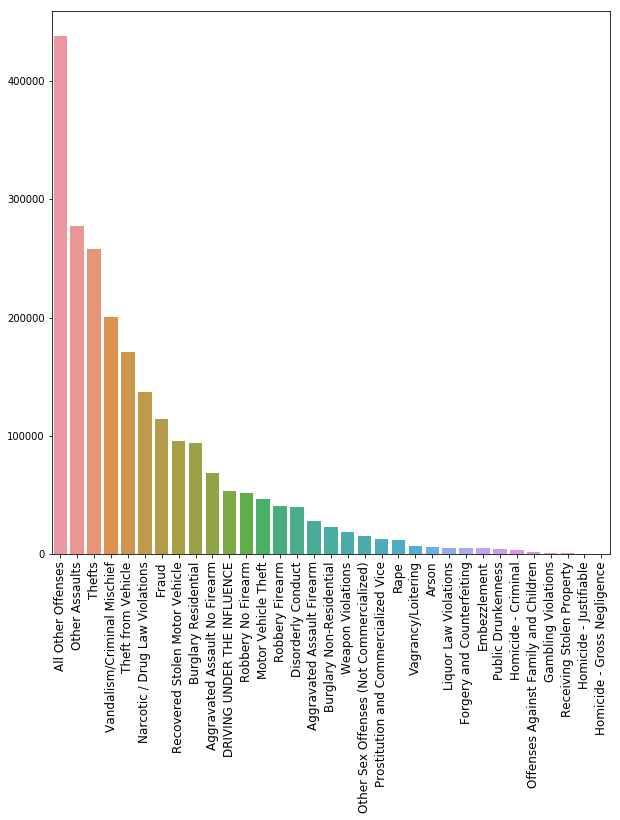
En el gráfico se puede apreciar con mucha facilidad que la mayoría de los crímenes están registrados bajo All other offenses y Other assaults es decir, que no describen específicamente de qué crímenes se trata. ¿Cuantos crímenes estan bajo éste código de clasificación?.
La clase Series de pandas nos ofrece el método Series.drop que remueve registros y Series.sum el cual devuelve la cantidad de registros.
# Cantidad de crímenes bajo categorías bien definidas
unidentifiedCrimes = crimesCountedByType\
.drop("All Other Offenses")\
.drop("Other Assaults")\
.sum()
# Cantidad de crímenes bajo las categorías de "Otros"
identifiedCrimes = crimesCountedByType\
.drop("Thefts")\
.drop("Vandalism/Criminal Mischief")\
.drop("Theft from Vehicle")\
.drop("Narcotic / Drug Law Violations")\
.drop("Fraud")\
.drop("Recovered Stolen Motor Vehicle")\
.drop("Burglary Residential")\
.drop("Aggravated Assault No Firearm")\
.drop("DRIVING UNDER THE INFLUENCE")\
.drop("Robbery No Firearm")\
.drop("Motor Vehicle Theft")\
.drop("Robbery Firearm")\
.drop("Disorderly Conduct")\
.drop("Aggravated Assault Firearm")\
.drop("Burglary Non-Residential")\
.drop("Weapon Violations")\
.drop("Other Sex Offenses (Not Commercialized)")\
.drop("Prostitution and Commercialized Vice")\
.drop("Rape")\
.drop("Vagrancy/Loitering")\
.drop("Arson")\
.drop("Liquor Law Violations")\
.drop("Forgery and Counterfeiting")\
.drop("Embezzlement")\
.drop("Public Drunkenness")\
.drop("Homicide - Criminal")\
.drop("Offenses Against Family and Children")\
.drop("Gambling Violations")\
.drop("Receiving Stolen Property")\
.drop("Homicide - Justifiable")\
.drop("Homicide - Gross Negligence")\
.sum()
De ésta manera, podemos ver el porcentaje de crímenes que no están bien identificados.
# Calculo de la relación porcentual
100.0 * identifiedCrimes / (identifiedCrimes + unidentifiedCrimes)
>> 31.95938920186576
Ahora bien, en el gráfico anterior no se pueden advertir, con exactitud, las relaciones de la cantidad de crímenes en cada categoría con respecto al total. ¿Cuáles son estas relaciones y cómo podemos visualizarlas?.
# Serie de datos con el conteo de crímenes
crimesGroupByType = pd.Series(crimeData\
.Text_General_Code\
.value_counts()\
).reset_index()
# Renombramos las columnas
crimesGroupByType.rename(columns = {\
'Text_General_Code': 'Total',\
'index': 'Category'
},\
inplace=True\
)
# Seteamos el índice en la columna de categorías
crimesGroupByType.set_index("Category", inplace=True)
# Sumamos la cantidades para obtener el total entre todos las categorías
totalCrimes = crimesGroupByType.Total.sum()
# Calculamos el porcentaje de crímenes por categoría
meanCrimesInCategory = crimesGroupByType\
.Total\
.apply(lambda totalInCategory: (100.0 * totalInCategory / totalCrimes))
Porcentaje por categoría usando gráfico de barras
plt.subplots(figsize=(10, 10))
g = sns.barplot(x=meanCrimesInCategory.index.tolist(), y=meanCrimesInCategory.values);
g.set_xticklabels(rotation=90, labels=meanCrimesInCategory.index.tolist(), fontsize=12);
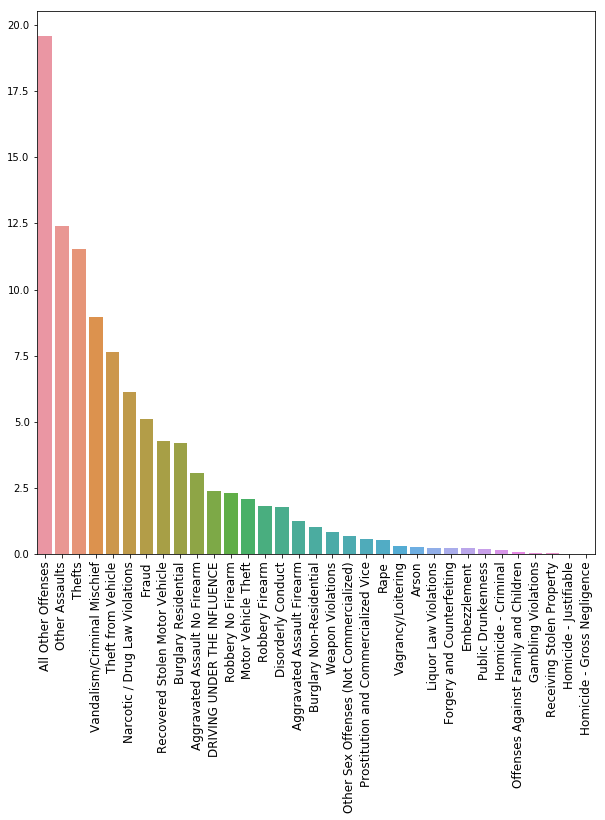
Porcentaje por categoría usando mapa de calor
sns.heatmap(crimesGroupByType)
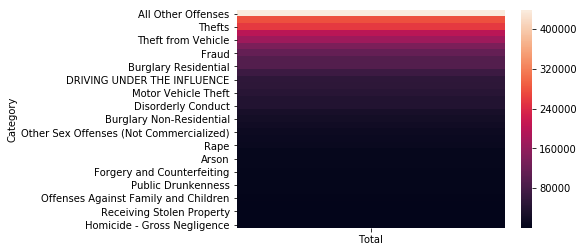
Conclusiones
La mayoría de los crímenes en la ciudad de Filadelfia (69%) no están identificados bajo una categoría propia, esto puede significar que acumulan varias categorías menores, o bien, como en las categorías específicas de crímenes están los tipos más graves, es posible que “Otros” contenga los de menor gravedad.
No obstante, entre los crímenes identificados más comunes están los Robos, el vandalismo y el uso, tenencia o distribución de narcóticos y entre los menos comunes están los homicidios.
Incidencia de crímenes por año
Estudiemos como se comportan los crímenes a través de los años usando métodos en la sección anterior. Recordemos que la columna que indica el mes del crimen, incluye también el año.
# Interpretamos la columna de mes usando datetime
crimeData.Month = crimeData\
.Month\
.apply(lambda givenMonth: datetime.strptime(givenMonth, "%Y-%m"));
# Mapeamos la columna al año que indica
crimesByYears = crimeData\
.Month\
.map(lambda x: x.year)\
.value_counts()
# Echamos un vistazo al resultado
crimesByYears
Como resultado, tenemos una Serie en la que cada año se relaciona con los crímenes registrados en esas fechas y, en primera instancia, se puede ver que los crímenes van decreciendo poco a poco en el tiempo. ¿Cómo podemos graficar y evidenciar éste resultado?
2006 234755
2007 223902
2008 223735
2009 205044
2010 199415
2012 196755
2011 195521
2013 186489
2014 186146
2015 183300
2016 169101
2017 33442
Name: Month, dtype: int64
Crímenes por año utilizando gráfico de barras
# Con el parámetro log, indicamos a seaborn que use una
g = sns.barplot(\
y=crimesByYears.index.tolist(),\
x=crimesByYears.values,\
log=True\
);
# Rotamos las etiquetas para hacer mas facil la lectura
g.set_xticklabels(\
rotation=90,\
labels=crimesByYears.index.tolist(),\
fontsize=12\
);
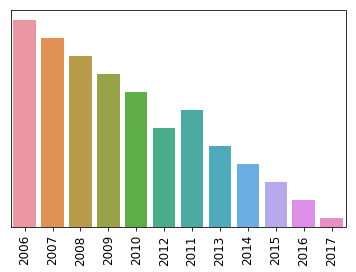
¿Cómo cambió la criminalidad entre el 2006 y el 2016?
100.0 * crimesByYears[2016] / crimesByYears[2006]
>> 72.03297054375838
Conclusiones
La incidencia de crímenes tiene una tendencia bajista de hecho, en 10 años se ha reducido en casi un 30%.
Crímenes por ubicación
Otra perspectiva que nos conscierne estudiar es ¿Cuales son las zonas en las que hay más crímen?. Veamos primeramente en un gráfico de puntos las latitudes y longitudes, haciendo una ventana aleatorea de la mitad de los datos. Para ello, utilizamos el método seaborn.scatterplot.
# Sacamos los registros sin latitud y longitud
totalCrimes = crimeData.dropna().shape[0]
# Hacemos una ventana de los datos
crimeDataSample = crimeData.sample(totalCrimes // 2)
# Tomamos la ubicación geográfica
lats = (crimeDataSample.Lat * 10e4)
longs = (crimeDataSample.Lon * 10e4)
sns.scatterplot(y=lats, x=longs, alpha=0.1, s = 2, legend = False)
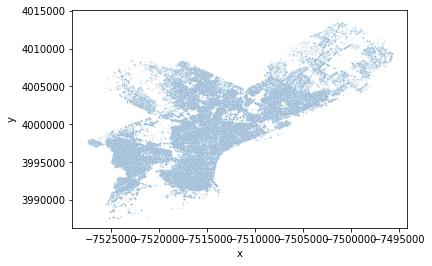
Como resultado, se pueden contemplar que los puntos que rellenan todo el mapa de Filadelfia, con algunos sitios mas poblados que otros.

Mapa de crímenes en el 2016 usando gráfico de puntos
# Generamos una mascara de los crímenes en el año 2016
recentCrimesMask = crimeData.Month.map(lambda x: x.year) == 2016
# Aplicamos la mascara a la data
recentCrimes = crimeData[recentCrimesMask]
# Obtenemos la ubicación correspondiente para cada caso
lats = (recentCrimes.Lat.dropna() * 10e4)
longs = (recentCrimes.Lon.dropna() * 10e4)
# Generamos un DataFrame con estos datos
crimeMap = pd.DataFrame({ 'x': longs, 'y': lats })
# Creamos un gráfico de puntos con scatterplot
sns.scatterplot(y=crimeMap.y, x=crimeMap.x, alpha=0.1, s = 2, legend = False)
Mapa de crímenes usando puntos coloreados por categoría
# Obtenemos la columna de categorías desde el DataFrame
recentCrimesTypes = recentCrimes.Text_General_Code
# Utilizamos el parámetro hue en scatterplot, para diferenciar los tipos de puntos
sns.scatterplot(\
y=crimeMap.y,\
x=crimeMap.x,\
hue = recentCrimesTypes,\
alpha=.5,\
s = 5,\
legend = False\
)
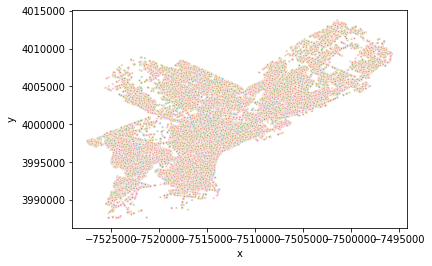
Conclusión
En la zona del aeropuerto de Filadelfia y en la zona limítrofe con Pensilvania, los crímenes son menores que en el resto de las zonas.
Zonas en Filadelfia con mayor criminalidad
Otro enfoque posible para la pregunta anterior es utilizar gráficos de densidad. Veamos dos cosas: un mapa de Filadelfia real y un gráfico de estimación de densidad por kernel.
# Leemos la data que corresponde a la imagen
philadelphiaMap = cbook.get_sample_data(\
'resources/map.jpeg'\
)
philadelphiaImage = imread(philadelphiaMap)
# Mostramos la imagen
plt.imshow(\
philadelphiaImage,\
zorder=0,\
extent=[0.5, 8.0, 1.0, 7.0]\
)
plt.show()
# Creamos un gráfico de densidad por kernel
sns.kdeplot(\
lats,\
longs,\
cmap="Reds",\
shade=True,\
cut=0\
)
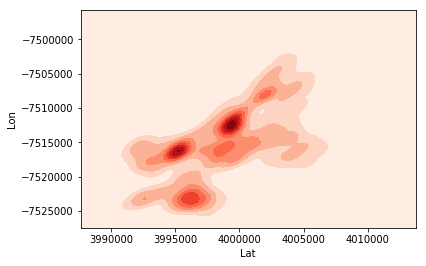
Estudiando por bloques específicos
Se puede apreciar en las gráficas anteriores que existen dos zonas con mayor densidad de crímenes que en las demás (al centro al noreste) y también existe una zona con densidad moderada-alta respecto a las demás. Veamos cómo podemos visualizar estas zonas, utilizando el mapa de Filadelfia y para ello, tomaremos como ejemplo, la zona del centro.
Crímenes en el centro de Filadelfia
Comencemos con un gráfico de puntos como los que hicimos anteriormente. Notaremos que en esta zona, hay una curva en la que no aparecen crímenes, esto es porque ahí pasa el Río Schuylkill.
# Utilizamos las gráficas para tomar coordenadas de referencia
# Hacemos mascaras de índices que cumplan con estar dentro del centro
longitudeMask = crimeData.Lon.map(lambda x: (x > -75.2) and (x < -75.15)) == 1.0
latitudeMask = crimeData.Lat.map(lambda x: (x > 39.925) and (x < 39.975)) == 1.0
crimesInCenterBlockMask = (longitudeMask) & (latitudeMask)
# Aplicamos la máscara a la data
crimesInCenterBlock = crimeData[crimesInCenterBlockMask]
# Visualizamos el registro con puntos
sns.scatterplot(\
y = crimesInCenterBlock.Lat, \
x = crimesInCenterBlock.Lon, \
hue = crimesInCenterBlock.Text_General_Code, \
alpha = .5, \
s = 5, \
legend = False \
)
# La zona con menos puntos, es el Río Schuylkill

Para poner en contexto, utilizamos Leaflet para dibujar un cuadro con la zona que hemos estudiado. En una notebook de Jupyter, está la libreria ipyleaflet, que permite la exportación de widgets de mapas.
# from ipyleaflet import *
# Creamos un mapa
m = Map(\
center=(39.925, -75.2),\
zoom=10,\
basemap=basemaps.OpenStreetMap.Mapnik\
);
# Creamos un polígono con el cuadro
polygon = Polygon(\
locations = [\
(39.925, -75.2),\
(39.975, -75.2),\
(39.975, -75.15),\
(39.925, -75.15)\
],\
color = "green",\
fill_color = "green"\
);
# Agregamos el polìgono al mapa
m.add_layer(polygon);
# Y lo mostramos
m
Tipos de crímenes en la zona del centro
Contando por categoría y viendo los primeros resultados, hacemos otro hallazgo.
crimesInCenterBlock.Text_General_Code\
.value_counts()\
.head()
All Other Offenses 67236
Thefts 64685
Other Assaults 34626
Theft from Vehicle 30414
Vandalism/Criminal Mischief 27365
Name: Text_General_Code, dtype: int64
Es claro que los robos Thefts representan una parte importante de los crímenes en esta zona. No obstante, volvamos a la pregunta ¿Qué porcentaje de crímenes representan los del centro de Filadelfia?
100.0 * (crimesInCenterBlock.count() / crimeData.count())[0]
>> 15.315705855144227
Conclusion
Los crímenes en la zona central de hecho, representan un 15% del total.
Crímenes por hora
Otra pregunta interesante que nos podemos hacer es ¿Cual es la distribución de ocurrencia de crímenes respecto las horas?. Podemos conjeturar momentos mas seguros o inseguros en el día. Veamos una gráfica de distribución que nos explique los hechos con el método seaborn.distplot
totalCrimes = crimeData.dropna().shape[0]
sns.distplot(crimeData.sample(totalCrimes // 2).Hour);
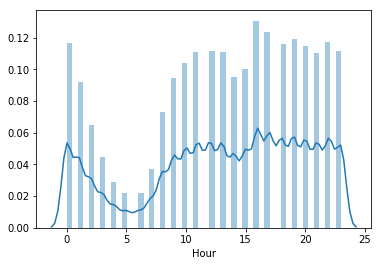
Conclusion
Los horarios en los que se registran menos crímenes es en la mañana, concretamente entre las 4am y 6am.

Comentarios